
Medidas de variabilidad
Dispersión: La dispersión se refiere a la extensión de los datos, es decir al grado en que las observaciones se distribuyen (o se separan).
Existen otras dos características de los conjuntos de datos que proporcionan información útil: el sesgo y la curtosis.
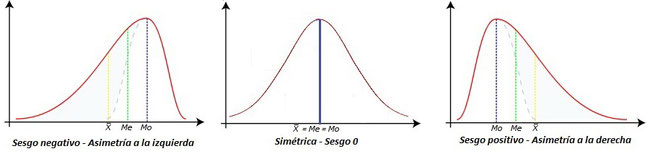
Sesgo: Las curvas que representan un conjunto de datos pueden ser simétricas o sesgadas. L as curvas simétricas tienen una forma tal que una línea vertical que pase por el punto más alto de la curva, divide al área de ésta en dos partes iguales. Si los valores se concentran en un extremo se dice sesgada. Una curva tiene sesgo positivo cuando los valores van disminuyendo lentamente hacia el extremo derecho de la escala y sesgo negativo en caso contrario.
El sesgo es una medida de la asimetría de la curva. En general es un valor que va de -3 a 3. Una curva simétrica toma el valor 0.
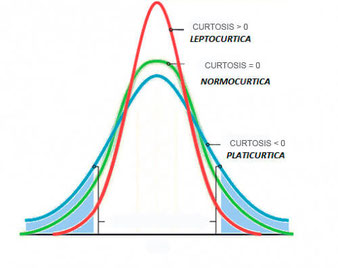
Curtosis: Nos da una idea de la agudeza (o lo plano) de la distribución de frecuencias.. Una curva normal (es el patrón con el que se compara la curtosis de otras curvas) tiene curtosis 0.
Esta curva se llama mesocúrtica. Si la curtosis es mayor que 0, la curva es más empinada que la anterior y se denomina leptocúrtica (Lepto, del griego, "empinado" o "estrecho"). Si la curtosis es menor que 0, es relativamente plana y se denomina platicúrtica ("plano", "ancho").
MEDIDAS DE DISPERSIÓN
Las medidas de dispersión son útiles porque:
Nos proporcionan información adicional que nos permite juzgar la confiabilidad de nuestra medida de tendencia central. Si los datos están muy dispersos la posición central es menos representativa de los datos, como un todo, que cuando estos se agrupan más estrechamente alrededor de la media.
Ya que existen problemas característicos de distribuciones muy dispersas, debemos ser capaces de distinguir que presentan esa dispersión antes de abordar los problemas.
Nos permiten comparar varias muestras con promedios parecidos.
Los analistas financieros están preocupados por la dispersión de las ganancias de una empresa que van desde valores muy grandes a valores negativos. Esto indica un riesgo mayor para los accionistas y para los acreedores. De manera similar los expertos en control de calidad, analizan los niveles de calidad de un producto.
RANGO:
Es la diferencia entre el mayor y el menor de los valores observados.
\[R=X_n-X_1\]
Siendo x(n) la observación mayor y x(1) la observación menor.
- El rango es fácil de entender y de encontrar, pero su utilidad como medida de dispersión es limitada. Como sólo toma en cuenta el valor más alto y el valor más bajo ignora la naturaleza de la variación entre todas las demás observaciones, y se ve muy influido por los valores extremos.
- Debido a que considera sólo dos valores tiene muchas posibilidades de cambiar drásticamente de una muestra a otra en una población dada.
- Las distribuciones de extremo abierto no tienen rango.
VARIANZA Y DESVIACIÓN ESTÁNDAR
Las descripciones más comprensibles de la dispersión son aquellas que tratan con la desviación promedio con respecto a alguna medida de tendencia central. Veremos dos medidas que nos dan una distancia promedio con respecto a la media de la distribución: varianza y desviación estándar.
| Vaianza de la muestra |
| Es el promedio de las distancias al cuadrado que van de las observaciones a la media. La desviación estándar es la raíz cuadrada de la varianza. |
Las expresiones para el cálculo de la varianza y desviación estándar muestral son:
Datos sin agrupar
Varianza muestral
\[s^2 = \frac{\sum_{i=1}^{n}(x_i-\overline{x})}{n-1}\]
Ejemplo: Los siguientes datos representan una muestra de la cantidad de pedidos diarios entregados :
17 25 28 27 16 21 20 22 18 23
Hallar el rango, la varianza y la desviación estándar e interpretar.
Solución
a) Para hallar el rango ordenamos el conjunto de mayor a menor
16 17 18 20 21 22 23 25 27 28
R = x(10) – x(1) = 28 – 16 = 12
b) Para el cálculo de la varianza conviene realizar un cuadro:
|
x i |
x
|
x - x i |
(x - x i )2 |
xi2 |
|
16 |
21,7 |
-5,7 |
32,49 |
256 |
|
17 |
21,7 |
-4,7 |
22,09 |
289 |
|
18 |
21,7 |
-3,7 |
13,69 |
324 |
|
20 |
21,7 |
-1,7 |
2,89 |
400 |
|
21 |
21,7 |
-0,7 |
0,49 |
441 |
|
22 |
21,7 |
0,3 |
0,09 |
484 |
|
23 |
21,7 |
1,3 |
1,69 |
529 |
|
25 |
21,7 |
3,3 |
10,89 |
625 |
|
27 |
21,7 |
5,3 |
28,09 |
729 |
|
28 |
21,7 |
6,3 |
39,69 |
784 |
|
|
|
|
152,1 |
4861 |
\[\begin{align*} s^2 &= \frac{\sum_{i=1}^{n}(x_i-\overline{x})}{n-1}\\ &=\frac{152,1}{10-1}\\ &=16,9\\ s&=\sqrt{s^2}\\ &=\sqrt{16,9}\\ &=4,11 \end{align*}\]
En promedio, la cantidad de pedidos se separa de la media en, 4,11 pedidos.
Datos agrupados
Varianza muestral
\[\begin{align*} s&=\sqrt{\frac{\sum (m_i-\overline{x})f_i}{n-1}} \\ &=\frac{\sum m_i^2f_i-\frac{(\sum m_if_i)^2}{n}}{n-1} \end{align*}\]
Desviación estándar muestral
\[s=\sqrt{s^2}\]
Donde:
s2 : Varianza de la muestra
s : Desviación estándar de la muestra
fi : Frecuencia absoluta de la clase i
mi : Marca de la clase i
Media de la muestra
n : Tamaño de la muestra
Ejemplo: Los estadísticos del programa de Meals on Wheels (comida sobre ruedas), el cual lleva comidas calientes a enfermos confinados en casa, desean evaluar sus servicios. El número de comidas que suministran aparece en la siguiente tabla:
|
Número de comidas por día |
Número de días |
|
0 – 5 |
3 |
|
6 – 11 |
6 |
|
12 – 17 |
5 |
|
18 – 23 |
8 |
|
24 – 29 |
2 |
|
30 - 35 |
3 |
Calcular la media, la mediana, la moda, la varianza y la desviación estándar de comidas diarias.
Se requiere construir el siguiente cuadro:
|
Número de comidas por día
|
Punto medio mi (1) |
Frecuencia fi (2) |
mifi
(3)=(1)(2) |
fi
(4) = (1)(3) |
|
0 – 5 |
2,5 |
3 |
7,5 |
18,75 |
|
6 – 11 |
8,5 |
6 |
51,0 |
433,50 |
|
12 – 17 |
14,5 |
5 |
72,5 |
1051,25 |
|
18 – 23 |
20,5 |
8 |
164,0 |
3362,00 |
|
24 – 29 |
26,5 |
2 |
53,0 |
1404,50 |
|
30 - 35 |
32,5 |
3 |
97,5 |
3168,75 |
|
|
|
27 |
445,5 |
9438,75 |
Cálculo de la media:
\[\begin{align*} \overline{x}&=\frac{\sum m_if_i}{n}\\ &=\frac{445,5}{27}\\ &=16,5 \end{align*}\]
Cálculo de la mediana
\[\begin{align*} Me&=L_i+c\left ( \frac{\frac{n}{2}-F_{i-1}}{f_i} \right )\\ &=12+6\left (\frac{\frac{27}{2}-9}{5} \right )\\\ &=17,4 \end{align*}\]
Cálculo de la moda
\[\begin{align*} Mo&=L_i+c\left ( \frac{d_1}{d_1+d_2} \right )\\ &=18+6\left (\frac{3}{3+6} \right )\\\ &=20 \end{align*}\]
Cálculo de la varianza
\[\begin{align*} s^2&=\frac{\sum (m_i-\overline{x})f_i}{n-1} \\ &=\frac{\sum m_i^2f_i-\frac{(\sum m_if_i)^2}{n}}{n-1} \\ &=\frac{9438,75-\frac{(445,5)^2}{27}}{27-1} \\ &=80,31 \end{align*}\]
Cálculo de la desviación estándar
\[\begin{align*} s&=\sqrt{\frac{\sum (m_i-\overline{x})f_i}{n-1}} \\ &=\sqrt{80,31}\\ &=8,96 \end{align*}\]